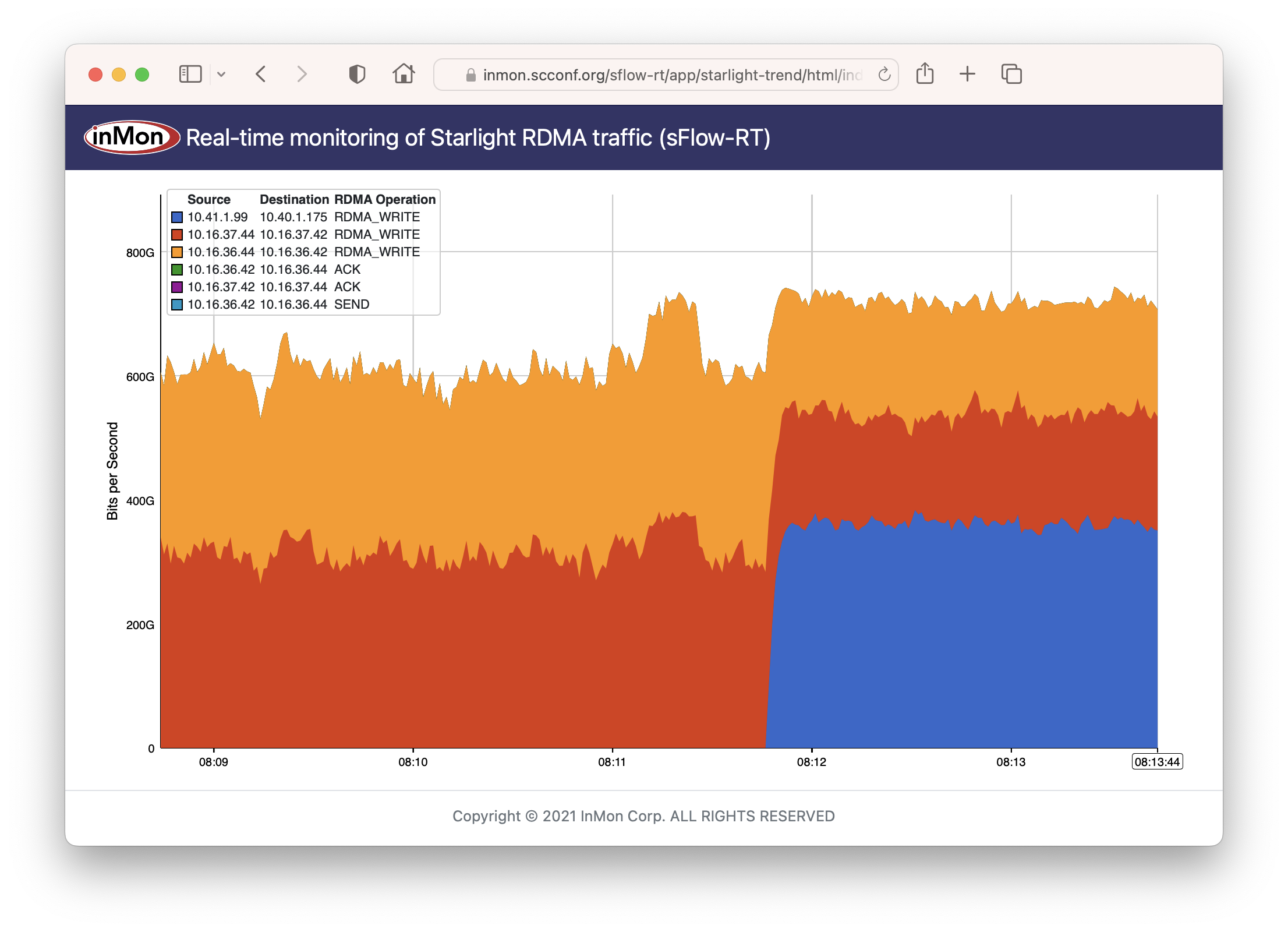
The chart shows eight 400Gbits/s
RDMA over Converged Ethernet (RoCEv2) flows, typically seen in AI / ML data centers, totaling 3.2 Tbits/s. The unique challenge in this case is that flows are being routed from locations scattered around the United States to Atlanta, the location of the
International Conference for High Performance Computing, Networking, Storage, and Analysis (SC24) conference.
SC24 Network Research Exhibit: The Resiliant, Performant Networks and Distributed Processing demonstration aims
to explore performance limitations and enablers for high volume bulk data tranfers. Maintaining stable 400Gbits/s RoCEv2 connections over a wide area network is challenging since the packets have to traverse multiple links, avoid contention on links, and deal with buffering associated with transmission latency that is orders of magnitude higher than data center environments where RoCEv2 is typically deployed (one way latency across the USA is a minimum of 16 milliseconds due to speed of light, but in practice the latency is quite a bit larger, on the other hand latency across a leaf and spine data center fabric is measured in microseconds).

During setup it was noticed that total throughput with 8 concurrent flows was only 2.7Tbits/s (instead of the 3Tbits/second plus expected). Examining a real-time view of the throughput revealed that the two smallest flows, pink and light green at the top of the chart, were likely sharing a 400Gbits path since each flow was only transferring 200Gbps. The next flow down, light blue, appeared to be unstable and wasn't maintaining a constant 400Gbps.
Drilling down to look at the unstable flow showed that it was oscilating between 280Gbits/s and 400Gbits/s with a period of around 15 seconds. Further investigation revealed that the cause of the instability was a collision with a smaller flow on one of the links traversed by this flow. Once the flow collisions were resolved, all flows achieved close to 400Gbit/s, allowing the full 3Tbits/s transfer rate shown at the top of this article.
In this example, the
sFlow-RT real-time analytics engine receives sFlow telemetry from switches, routers, and servers in the
SCinet network and creates metrics to drive the real-time charts.
Getting Started provides a quick introduction to deploying and using sFlow-RT for real-time network-wide flow analytics.
Real-time network visibility is particularly relevant to AI / ML data center networks where congestion and dropped packets can result in serious performance degredation of machine learning tasks. Industry standard sFlow instrumentation is supported by the high speed 400/800G switches currently being deployed in AI / ML data centers. Enabling sFlow analytics provides the visibility needed to optimize performance.
Network visibility complements existing system management tools used to provide visibility into compute nodes, extending visibility into the fabric to directly observe problems in the network that can't easily be inferred from the compute nodes, and providing a second pair of eyes with an independent view of performance.
Finally, check out the SC24 Dropped packet visibility demonstration to learn about one of newest developments in sFlow monitoring and see a live demonstration.